“
4月1日,在2026中国IC领袖峰会“边缘AI与算力芯片”垂直技术论坛上,国科微AI算法部部长倪亚宇发表题为《FlashAttention-4:新一代大模型推理NPU流水线范式设计》的主题演讲。
”
4月1日,在2026中国IC领袖峰会“边缘AI与算力芯片”垂直技术论坛上,国科微AI算法部部长倪亚宇发表题为《FlashAttention-4:新一代大模型推理NPU流水线范式设计》的主题演讲。

随着大模型加速走向产业落地,推理效率、内存带宽与系统功耗成为端侧部署的关键瓶颈。尤其在Transformer与大型语言模型持续演进的背景下,注意力机制(Attention)的高效实现,已成为芯片架构与工具链优化的重要突破口。
倪亚宇表示,国科微正聚焦FlashAttention等前沿技术在NPU平台上的落地探索,推动构建更适合端侧量产部署的NPU架构与工具链,为自动驾驶、边缘计算、智能终端及AIGC等场景提供高效能算力支撑。
NPU部署“满血版”FlashAttention仍面临挑战
作为大模型中的核心计算结构之一,注意力机制在实际运行中普遍面临访存开销高、流水线效率受限等问题。FlashAttention的提出,为解决这一问题提供了新的路径。
FlashAttention是由斯坦福大学Tri Dao等人于2022年提出的一种快速且内存高效的精确注意力算法。它通过对注意力计算过程进行等价重构,通过分块计算、在线Softmax、重计算与异步流水等方式,将中间计算过程保留在片上缓存中,减少外部存储访问带宽压力,显著提升推理效率。
在刚刚过去的3月中旬,FlashAttention 4.0版本正式发布。倪亚宇指出,FlashAttention从1.0演进至4.0,在并行性、长序列支持、低精度计算及异步执行等方面持续增强。但相较GPU,当前NPU在向量单元算力、异步流水排布、动态调度及超长上下文等能力上仍存差距。倪亚宇指出,要实现“满血版”FlashAttention,需围绕计算流水线、数据复用与系统带宽进行协同设计。
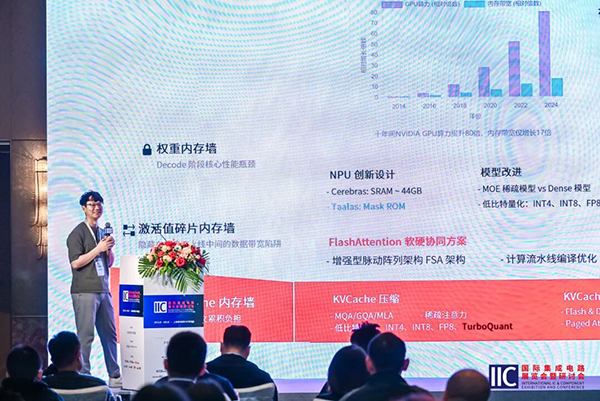
国科微NPU 4.0:构建更高效的推理单元
自2020年起,国科微持续投入NPU自主研发,形成从GKNPU 1.0到4.0的演进路线,产品能力向更高算力、更广模型覆盖与更优能效比升级。目前,国科微AI视觉与车载AI系列芯片已搭载3.0版本NPU,支持0.5T至8T算力,支持视觉、音频、时序等AI模型在端侧芯片应用落地。
在GKNPU 4.0架构设计中,国科微提出面向高效注意力计算的增强型脉动阵列架构,针对性扩展矩阵和向量计算能力,强化对大模型注意力机制中的关键操作的支持,压缩数据搬运路径与流水线开销,增强片上闭环计算能力。该设计旨在减少对外部带宽的依赖,提升推理链路执行效率,有效应对大模型推理中的带宽瓶颈、激活值碎片化及超长上下文的内存压力。
强化工具链,推动高效规模化部署
在NPU架构演进的同时,国科微持续强化工具链能力。新一代GKToolchain 3.0面向端侧异构算力场景,重点提升硬件感知编译、自动分块、自动向量化、异步数据读写与计算流水编排能力,推动模型部署从“可适配”迈向“高效率、可规模化”。
同时,工具链围绕动态内存管理、投机推理加速等前沿方向持续演进,增强对长上下文管理及复杂推理流程的支撑能力,助力客户高效完成从模型到芯片的部署闭环。
随着AI应用从训练侧走向推理侧、从云端走向终端,产业对算力平台的要求正从“高峰值性能”转向“高能效、可量产、易部署”的综合能力。NPU在端侧规模化落地中具备显著的成本与功耗优势。
倪亚宇表示,国科微将持续坚持算法与硬件协同创新,围绕大模型推理核心瓶颈,不断完善NPU架构、产品能力与工具链体系,推动端侧智能计算平台向更高性能、更低功耗、更强工程可落地方向演进,为客户提供更具竞争力的算力方案。
猜你喜欢






